昨天介紹完DNN而今天會講
卷積神經網絡(Convolutional Neural Network,CNN)大多用於處理和分析具有網格結構數據,如圖像和影片。CNN的獨特之處在於它使用卷積層(Convolutional Layers)和池化層(Pooling Layers),來自動從輸入數據中學習特徵。
這種架構使得CNN在圖像分類、物體檢測、影像分割等機器視覺任務中表現出色。它的成功來自於能夠捕捉局部特徵、減少參數數量以及具有平移不變性。CNN廣泛應用於計算機視覺領域,改變了圖像處理和分析的方式,下面再讓我們說明卷積層與池化層。
卷積層就像是一個過濾器,它在圖像上滑動,逐步檢測圖像的不同特徵,這些過濾器每次只處理圖像的一個小區域,並計算該區域的特徵。通過這樣的操作,卷積層可以捕捉到圖像中的局部特徵,並且具有平移不變性,意味著它能夠識別相同特徵的不同位置。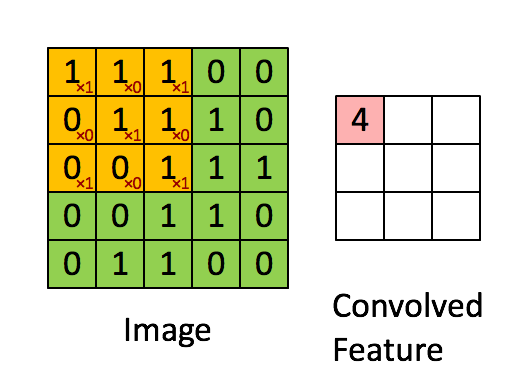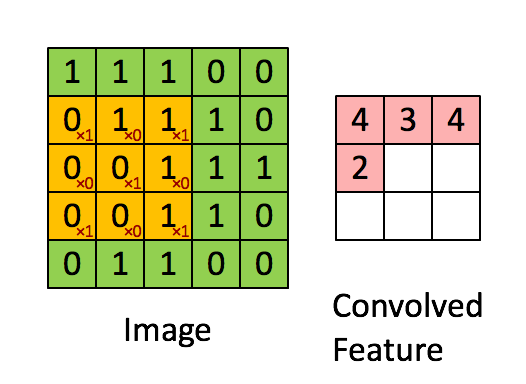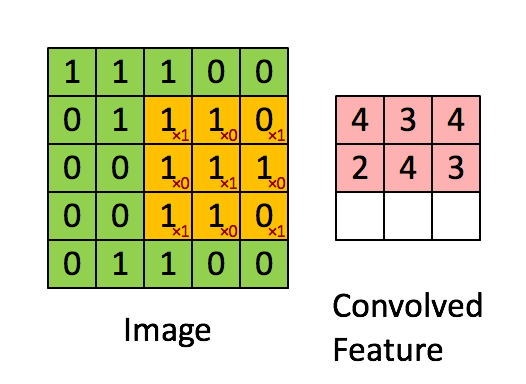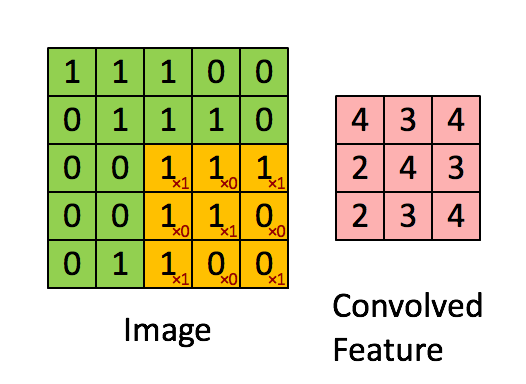
圖片來源:https://saturncloud.io/blog/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way/
卷積層包含多個卷積核,每個卷積核都是一個小的矩陣,它負責捕捉圖像中的特定特徵,如邊緣、紋理等。通過在輸入圖像上滑動卷積核,可以計算出特徵圖。
特徵圖是卷積操作的輸出,它是一個二維數組,包含了捕捉到的特徵信息。每個卷積核生成一個特徵圖,多個卷積核可以生成多個特徵圖。
步長是指卷積過程中卷積核(上圖移動的框框)在輸入數據上滑動的步伐(每次橫移格數)。它控制了卷積操作的輸出尺寸。較大的步長會導致輸出尺寸縮小,而較小的步長會保持較大的輸出尺寸。步長的選擇可以影響模型的特徵提取能力和計算效率。較小的步長可以提供更多的局部特徵信息,但計算代價較高。
填充是指在輸入數據的周圍添加額外的值(通常是0),以擴大輸入的尺寸,並控制卷積的輸出尺寸。
圖片來源:https://datahacker.rs/what-is-padding-cnn/
會看到與上面GIF圖不同,上方GIF便是沒有填充,輸出後的圖明顯少了一圈,因此填充通常用於控制特徵圖的大小,以便在不同層之間保持特徵圖的大小一致,這對於構建深度卷積神經網絡(CNN)模型很重要。
總之步長和填充是卷積操作中的重要參數,影響了模型的輸出尺寸和特徵提取能力,所以應根據具體的任務需求和模型架構進行調整,以達到最佳效果。
池化層(Pooling Layers)是一種特徵圖壓縮技術,通過對每個區域進行統計操作(通常是最大池化或平均池化)來減小特徵圖的尺寸,這種操作通常在卷積層後,有助於減少計算複雜度並提高模型的計算效率。
最大池化是最常見的池化操作之一。它在每個區域中選擇最大值作為代表,並將其用於新的特徵圖,有助於保留最重要的特徵,同時減小特徵圖的尺寸。
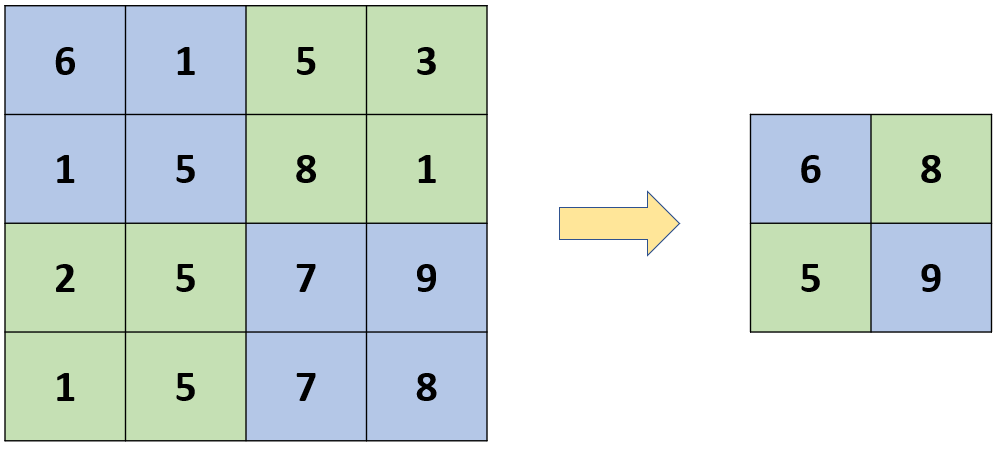
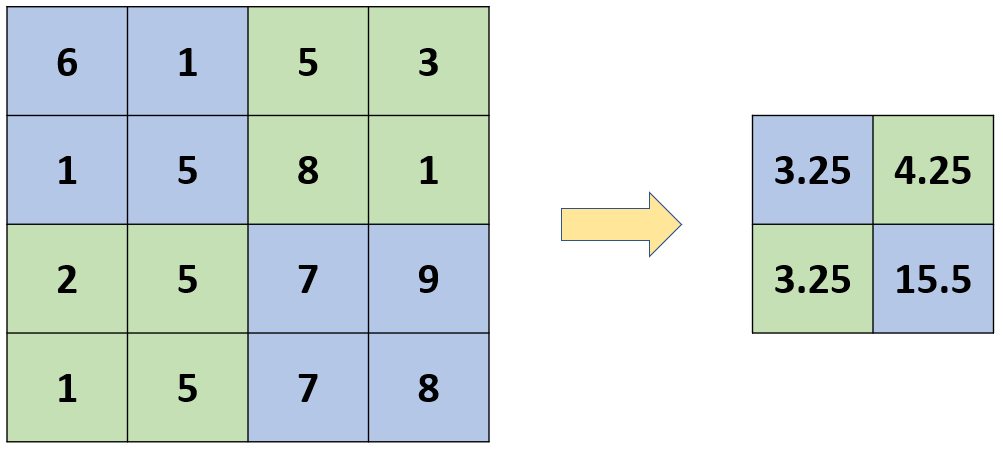
平均池化則是對每個區域中的值進行平均操作,而不是選擇最大值,這種池化方式也有助於減小特徵圖的尺寸,但可能會丟失一些細節信息。
以上就是關於CNN的說明
下面進入實作部分
今天我們的訓練集一樣是來自MNIST,不過這次使用的是當中的Fashion以下是他GitHub的介紹
其主題是來自10其他種類共700個不同商品的正面圖片,大小、格式和訓練集/測試集劃分與原始的MNIST完全一致。60000/10000的訓練測試資料劃分,28x28的灰階圖。
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping
import matplotlib.pyplot as plt
# 載入 Fashion MNIST 數據集
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# 數據預處理
x_train = x_train.reshape(-1, 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(-1, 28, 28, 1).astype('float32') / 255
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10)
# 創建卷積神經網絡(CNN)模型
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) # 卷積層 32特徵,卷積核3*3,激勵函數,輸入數據大小(28*28*1) 28*28圖 1為灰階(前面說過1大多黑白3為彩色)
model.add(MaxPooling2D(pool_size=(2, 2))) #池化 矩陣大小2*2
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) #池化 矩陣大小2*2
model.add(Flatten()) #攤平
model.add(Dense(128, activation='relu')) #全連接層
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) #全連接層
Conv2D(特徵數量, 卷積核3*3, 激勵函數,) Conv2D Keras中用於添加二維卷積層的函數
MaxPooling2D 二維最大池化
Dropout(輸出層隨機失活)是一種正則化技術,用於減少神經網絡的過度擬合。在每次訓練迭代中,Dropout會隨機將一部分神經元(通常是50%)暫時關閉,不參與前向和反向傳播,以阻止神經網絡對特定神經元的過度依賴。
# 編譯模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 定義早停回調函數以監控驗證集的損失
early_stopping = EarlyStopping(monitor='val_loss', patience=5, verbose=1)
# 訓練模型並使用早停回調函數
history = model.fit(x_train, y_train, batch_size=64, epochs=30, validation_split=0.2, callbacks=[early_stopping])
# 在測試集上評估模型
test_loss, test_accuracy = model.evaluate(x_test, y_test)
print(f"測試集上的準確率:{test_accuracy}")
# 輸出最後一個驗證集的損失
val_loss = history.history['val_loss'][-1]
print(f"最後一個驗證集的損失:{val_loss}")
這裡使用到了keras的early_stopping,它的用處在於訓練模型過程,若在設定次數內,模型沒有再進步則停止訓練,可以避免過擬合。
# 建立 LOSS 圖表
#train loss
plt.plot(history.history['loss'])
#test loss
plt.plot(history.history['val_loss'])
#標題
plt.title('Model loss')
#y軸標籤
plt.ylabel('Loss')
#x軸標籤
plt.xlabel('Epoch')
#顯示折線的名稱
plt.legend(['Train', 'Test'], loc='upper left')
#顯示折線圖
plt.show()
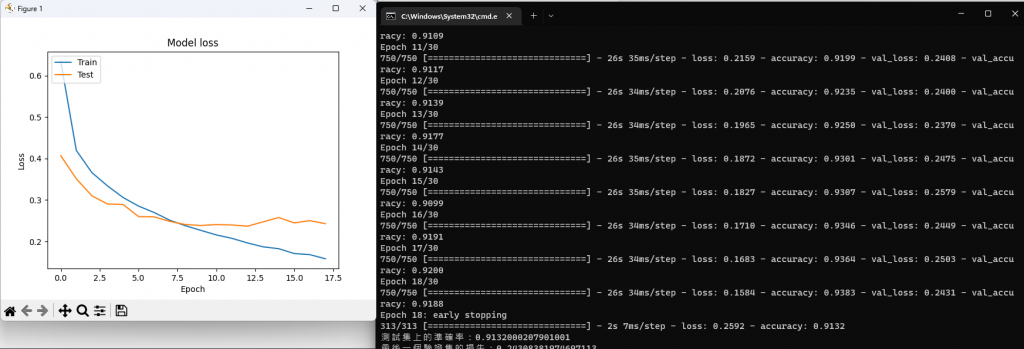
可以看到模型大概在7~8次訓練是最好的,並且模型在沒有再進步後即停止訓練,雖然early_stopping不會讓模型得到最好結果,但是能讓模型不會更糟還能避免過擬合。
以上就是CNN的介紹,如同前面介紹過CNN再圖片、影片等領域有著不錯表現,但這不代表DNN就比較差,而是要在不同情況選擇最適合的模型,在自行練習時也可以嘗試更改當中參數,也有助於讓自己了解程式在幹嘛,明天讓我們從RNN介紹起!明天見~

